High level architecture
While the application is deploying in CloudFormation (should take ~20 minutes), let’s talk about the architecture. The Bookstore Demo App is built on the AWS full stack template. Both of those links have excellent README.md files that go into depth on the architecture. We recommend that you read them, especially the Bookstore Demo App’s README
For this lab, we have added significantly to the Bookstore Demo App to enable monitoring and logging.
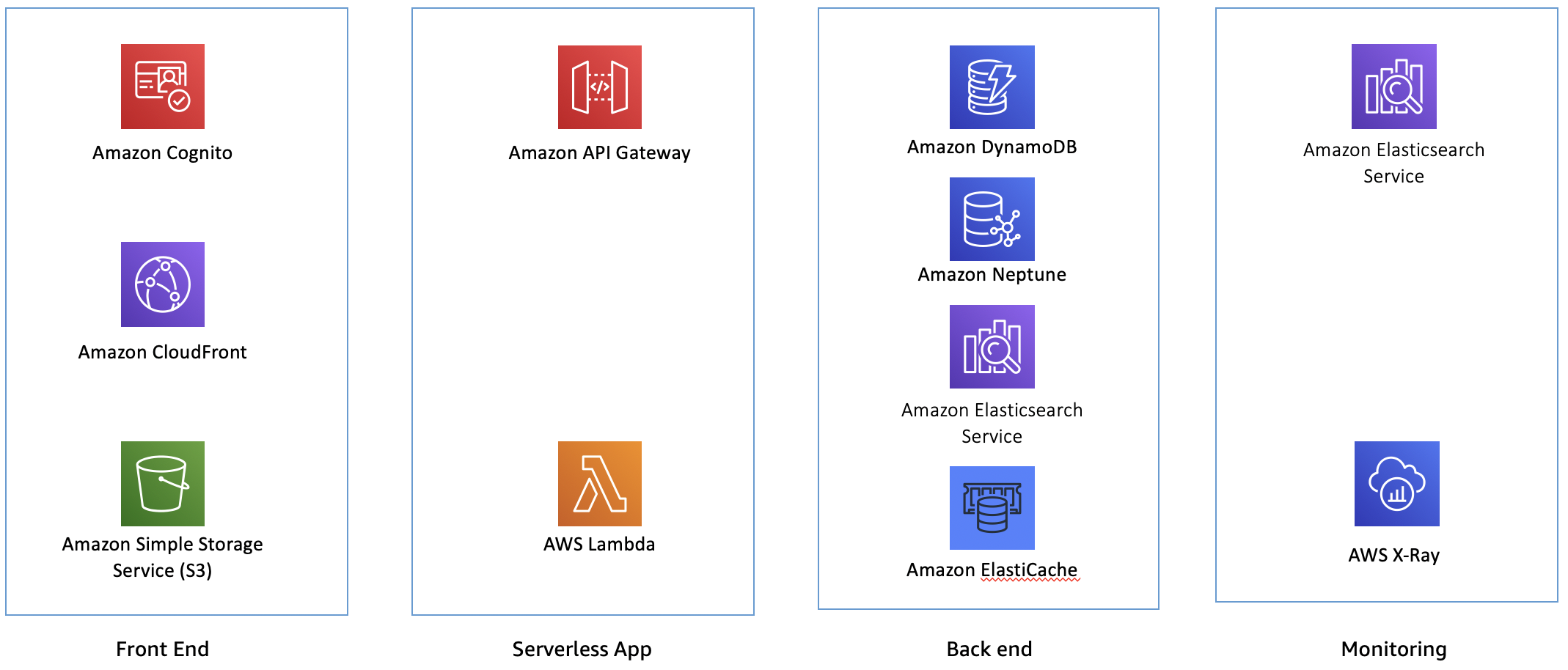
For the front end, you have Amazon Cognito providing authentication, Amazon CloudFront for serving assets, and Amazon S3 for hosting the application.
In the serverless app layer, you have Amazon API Gateway, backed by AWS Lambda for responding to API requests. All of the application traffic goes through this layer.
In the back end, you have Amazon DynamoDB serving the catalog of books, Amazon Neptune for tracking friends and making recommendations, Amazon Elasticsearch Service providing search across the books catalog, and Amazon Elasticache for Redis for maintaining best seller information.
At the monitoring layer, you have AWS X-Ray for distributed tracing and metrics, and Amazon Elasticsearch service for storing application and X-Ray logs.
Peeling back the onion to the next layer:
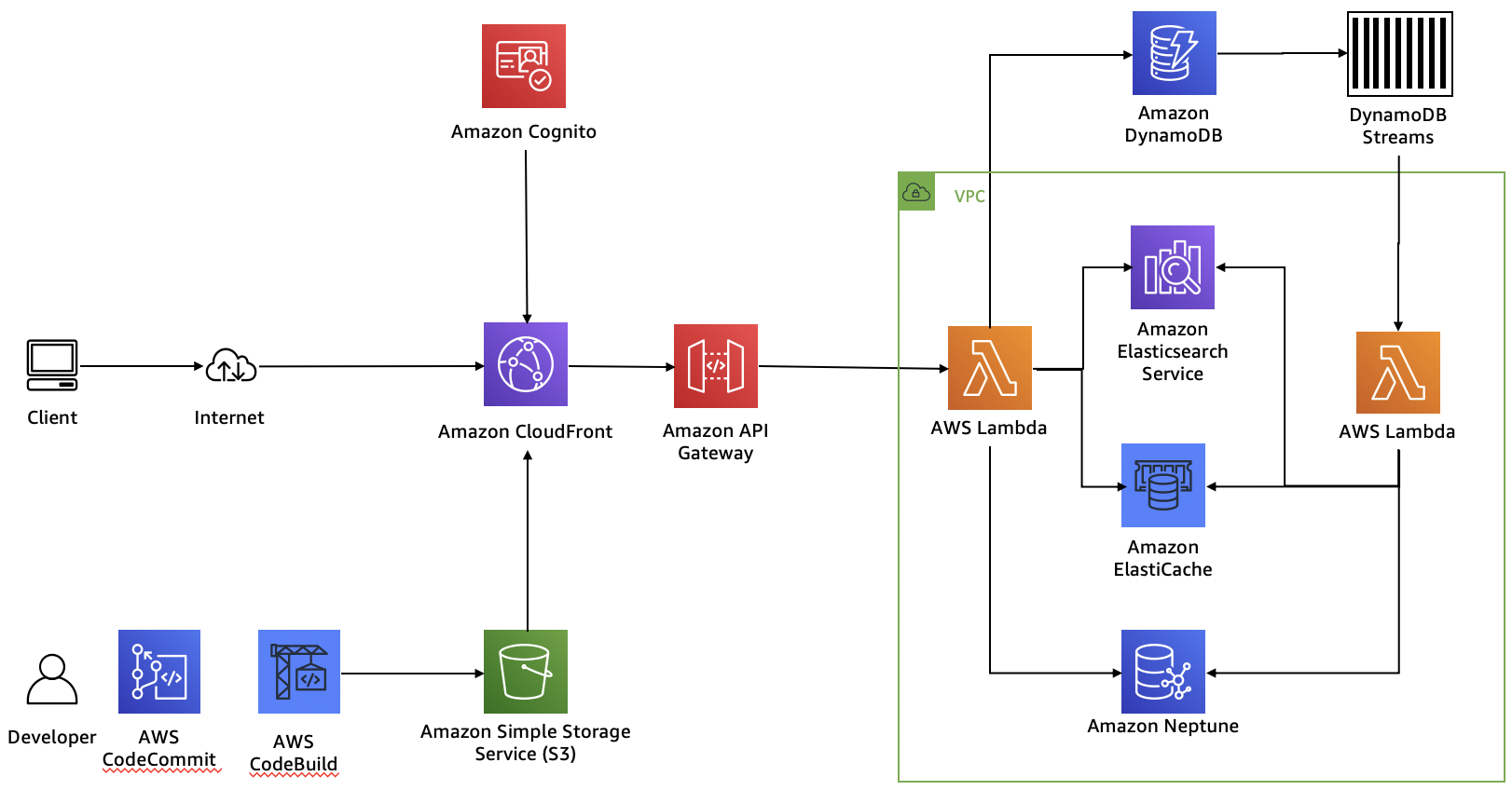
One pattern for building serverless applications is to use AWS Code Commit and AWS Code Build to create the application artifacts in S3. Amazon CloudFront loads these components and uses them to serve client requests. Along the way, Amazon Cognito provides authentication for website customers.
Amazon API Gateway powers the interface layer between the frontend and backend and invokes Lambda functions that interact with our purpose-built databases.
As updates come into DynamoDB (the database of record), they are sent through DynamoDB streams and an AWS Lambda function to forward changes to the Amazon ES domain, to Elasticache for Redis, and to Neptune.
For the monitoring layer
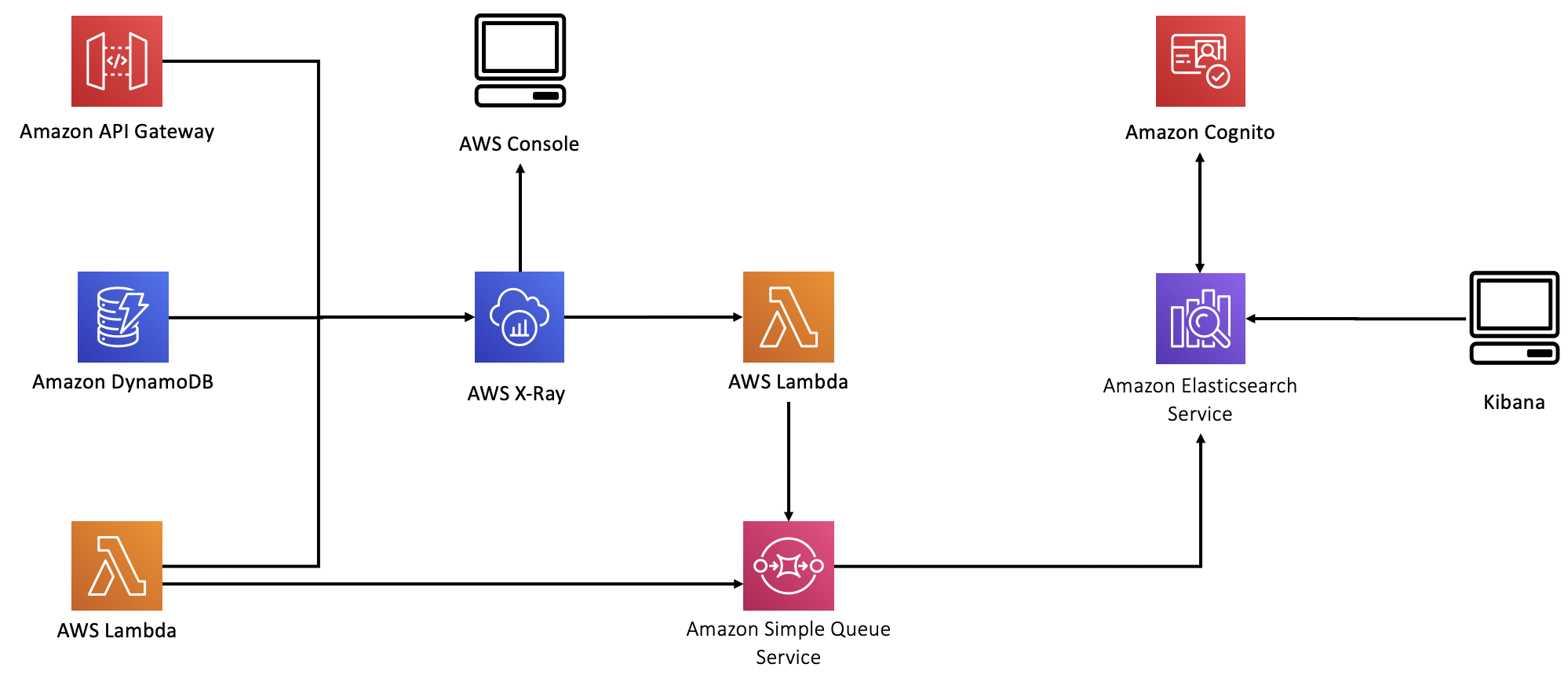
Lambda, API Gateway, and DynamoDB forward information to AWS X-Ray. In this lab, you will use the X-Ray console to explore this information.
We have also added a second Amazon ES domain to hold log data. As a general rule, it’s good to separate concerns and host search data in one domain and log data in a different domain. Because these two data types have such different access patterns, they scale quite differently. Also, by placing log data and search data in different domains, you reduce the blast radius. After all, you don’t want a problem with your logs preventing search on your front end application.
We chose to deploy the second Amazon ES domain outside of the VPC. This is really an anti-pattern. Best practice is to keep logging information inside the VPC, along with other sensitive data. We did it this way because providing access to the Amazon ES endpoint inside the VPC would greatly complicate the labs architecture, template, and this guide. This is a simplification that we chose because the data is not critical.
There are two sources of log data – AWS X-Ray and inline logging code in the Search, addToCart, and Checkout Lambda functions. We instrumented each of these Lambda functions, and we encourage you to have a look at them once they’re deployed (we’ll refer to this code throughout the lab guide).
To get X-Ray data, we built a scheduled Lambda that runs every minute, pulling data from X-Ray and sending it to Amazon ES.
In all cases, we used an Amazon Simple Queue Service (SQS) queue to collect data. We use a triggered Lambda to collect data from the queue and forward it to Amazon ES. This pattern is a very common part of any logging solution. While each component can send messages directly to Amazon ES, you will eventually overwhelm Amazon ES with too much concurrency. SQS serves here as a buffering layer to reduce concurrent connections.
If your stack has not finished deploying, browse the readme for AWS Bookstore Demo App. The Overview section provides a basic understanding of what the application consists of. The remainder of the readme file dives deeper, including the Architecture, Implementation details, and Considerations for demo purposes sections. This familiarization with how the app is structured will come in handy once deployment is complete and we browse the components of the application.